
在之前的两篇博文和中,我们对分词实现和词典实现都做了优化,本文对词典实现做进一步优化,并和之前的多个实现做一个对比,使用的词典,使用的测试文本。
优化TrieV3的关键在于把虚拟根节点(/)的子节点(词表首字母)提升为多个相互独立的根节点,并对这些根节点建立索引。优化的依据是根节点(词表首字母)的数量庞大,索引查找的速度远远超过二分查找。
下面看看进一步优化后的TrieV4和之前的TrieV3的对比:

/** * 获取字符对应的根节点 * 如果节点不存在 * 则增加根节点后返回新增的节点 * @param character 字符 * @return 字符对应的根节点 */ private TrieNode getRootNodeIfNotExistThenCreate(char character){ TrieNode trieNode = getRootNode(character); if(trieNode == null){ trieNode = new TrieNode(character); addRootNode(trieNode); } return trieNode; } /** * 新增一个根节点 * @param rootNode 根节点 */ private void addRootNode(TrieNode rootNode){ //计算节点的存储索引 int index = rootNode.getCharacter()%INDEX_LENGTH; //检查索引是否和其他节点冲突 TrieNode existTrieNode = ROOT_NODES_INDEX[index]; if(existTrieNode != null){ //有冲突,将冲突节点附加到当前节点之后 rootNode.setSibling(existTrieNode); } //新增的节点总是在最前 ROOT_NODES_INDEX[index] = rootNode; } /** * 获取字符对应的根节点 * 如果不存在,则返回NULL * @param character 字符 * @return 字符对应的根节点 */ private TrieNode getRootNode(char character){ //计算节点的存储索引 int index = character%INDEX_LENGTH; TrieNode trieNode = ROOT_NODES_INDEX[index]; while(trieNode != null && character != trieNode.getCharacter()){ //如果节点和其他节点冲突,则需要链式查找 trieNode = trieNode.getSibling(); } return trieNode; }
不同的字符可能会映射到同一个数组索引(映射冲突),所以需要给TrieNode增加一个引用sibling,当冲突发生的时候,可利用该引用将多个冲突元素链接起来,这样,在一个数组索引中就能存储多个TrieNode。如果冲突大量发生,不但会浪费已经分配的数组空间,而且会引起查找性能的下降,好在这里根节点的每个字符都不一样,冲突发生的情况非常少。我们看看词数目为427451的的冲突情况:
冲突次数为:1 的元素个数:2746冲突次数为:2 的元素个数:1冲突次数:2748总槽数:12000用槽数:9024使用率:75.2%剩槽数:2976



将词典文件和测试文本解压到当前目录下,使用下面的命令进行测试,需要注意的是,这里的-Xmx参数指定的值是相应的词典实现所需要的最小的堆空间,如果再小就无法完成分词:
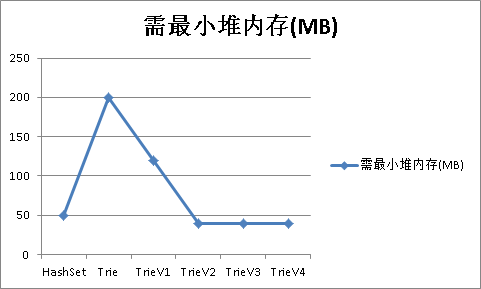
nohup java -Ddic.class=org.apdplat.word.dictionary.impl.TrieV4 -Xmx40m -cp target/word-1.0.jar org.apdplat.word.SegFile &nohup java -Ddic.class=org.apdplat.word.dictionary.impl.TrieV3 -Xmx40m -cp target/word-1.0.jar org.apdplat.word.SegFile &nohup java -Ddic.class=org.apdplat.word.dictionary.impl.TrieV2 -Xmx40m -cp target/word-1.0.jar org.apdplat.word.SegFile &nohup java -Ddic.class=org.apdplat.word.dictionary.impl.TrieV1 -Xmx120m -cp target/word-1.0.jar org.apdplat.word.SegFile &nohup java -Ddic.class=org.apdplat.word.dictionary.impl.Trie -Xmx200m -cp target/word-1.0.jar org.apdplat.word.SegFile &nohup java -Ddic.class=org.apdplat.word.dictionary.impl.HashSet -Xmx50m -cp target/word-1.0.jar org.apdplat.word.SegFile &
测试结果如下:



参考资料:
1、
2、
3、
4、
5、